When you purchase through links on our site, we may earn an affiliate commission.Heres how it works.
However, that is purely anecdotal and based on my experience, without backup from evaluations.
Ive decided to put them to the test with a series of 7 prompts.

As an aside, Grok is the only one who beat ChatGPT.
Creating the prompts
This test is not exhaustive.
Decisions are largely subjective and based on my own taste, albeit measured against a pre-determined set of criteria.
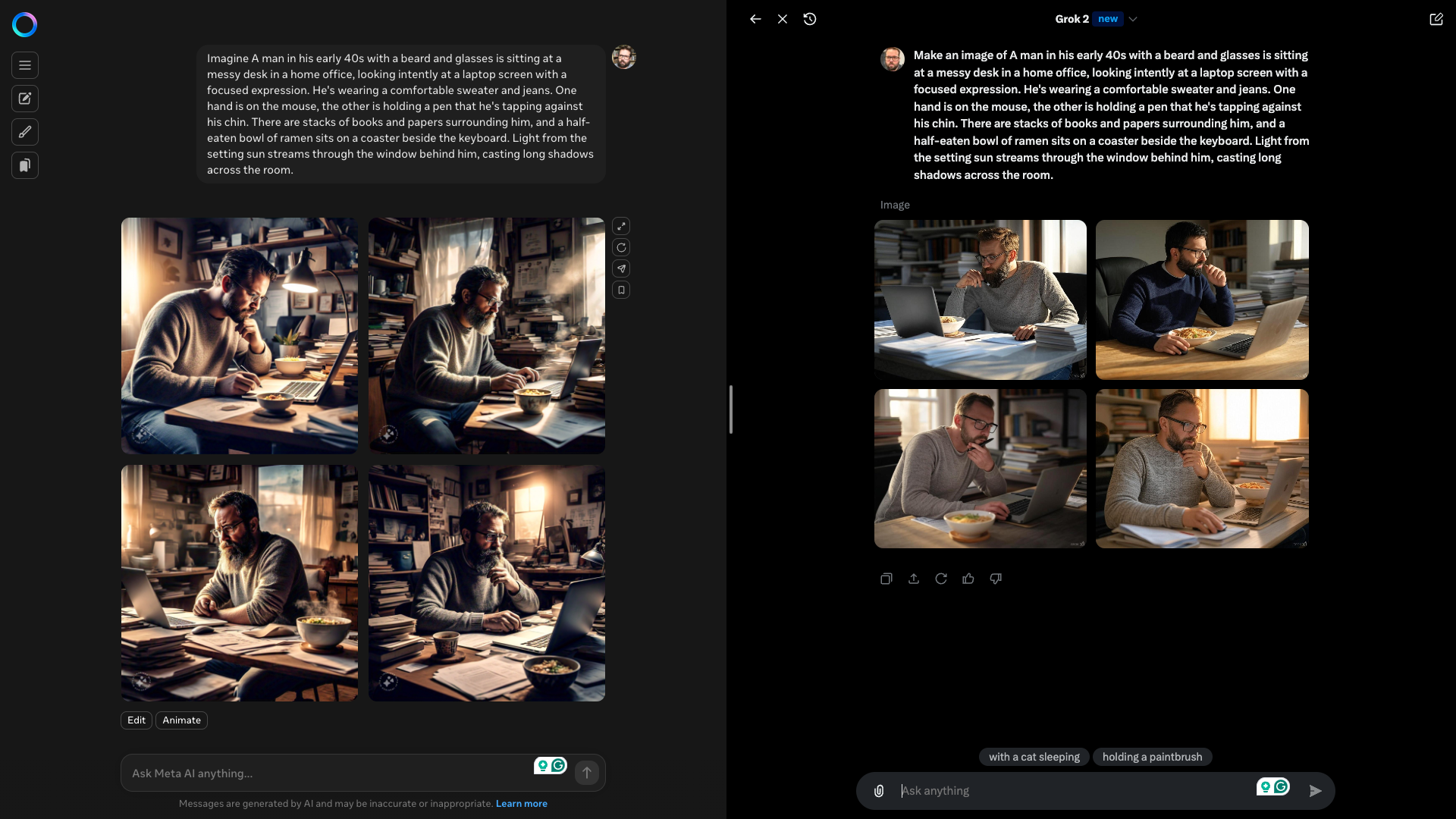
Image Generation
First up were going to fire off the AI image generation test.
Grok uses its own built-in model previously known as Aurora.
Gemini is using the Google DeepMind Imagen 3 model.

Neither are using native image generation, but then no public model uses that technique yet.
This is not autobiographical, honestly.
He’s wearing a comfortable sweater and jeans.
Light from the setting sun streams through the window behind him, casting long shadows across the room."
While MetaAI’s image is more engaging, it loses on realism compared to the Grok image.
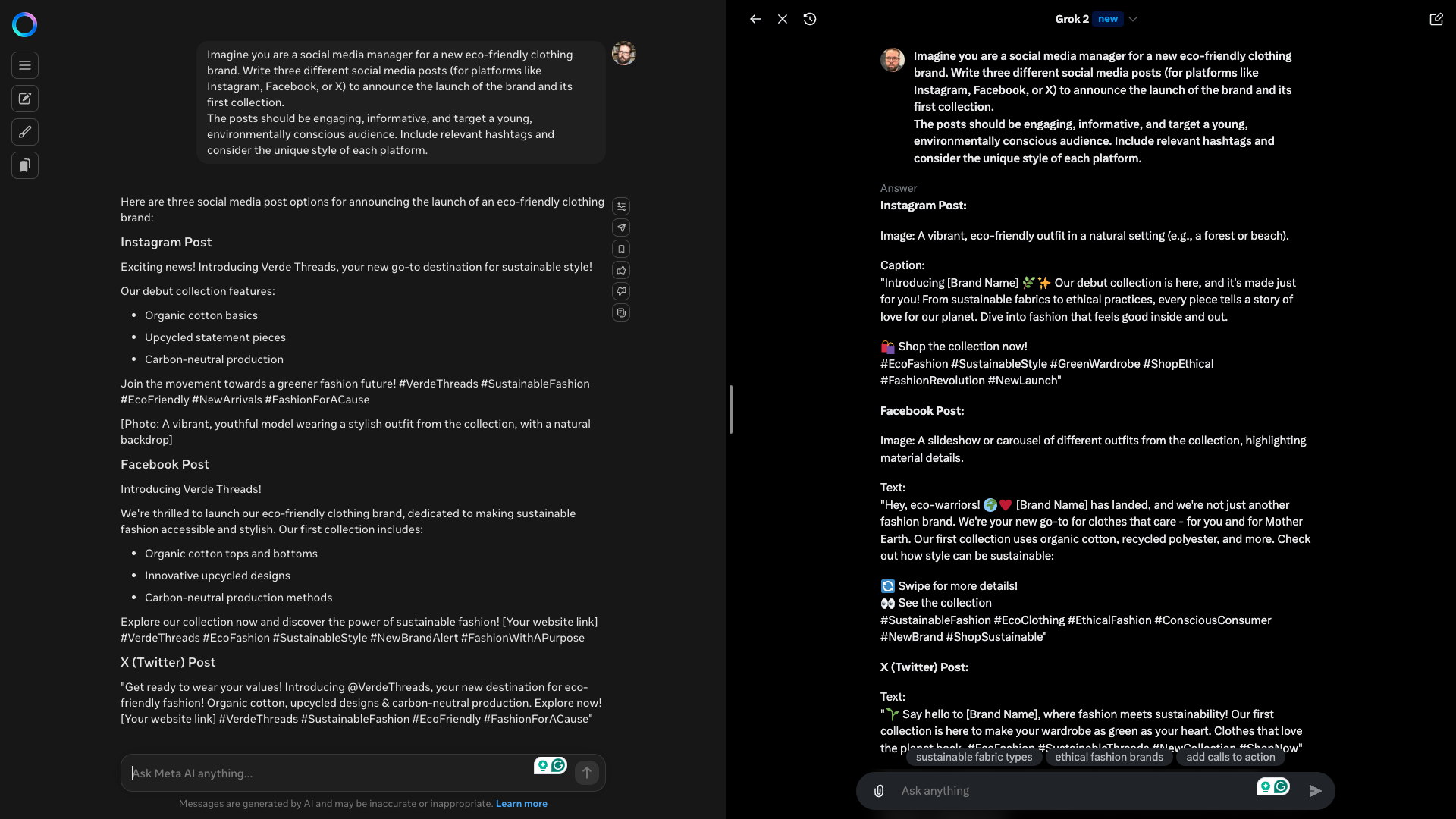
Prompt:“Imagine you are a social media manager for a new eco-friendly clothing brand.
The posts should be engaging, informative, and target a young, environmentally conscious audience.
Include relevant hashtags and consider the unique style of each platform.”
Full response in aGoogle Doc.
Grok wins this for multiple reasons, not least because it didn’t just make up a brand.
It created a placeholder campaign that the user can then insert their own brand into.
It also offered guidance.
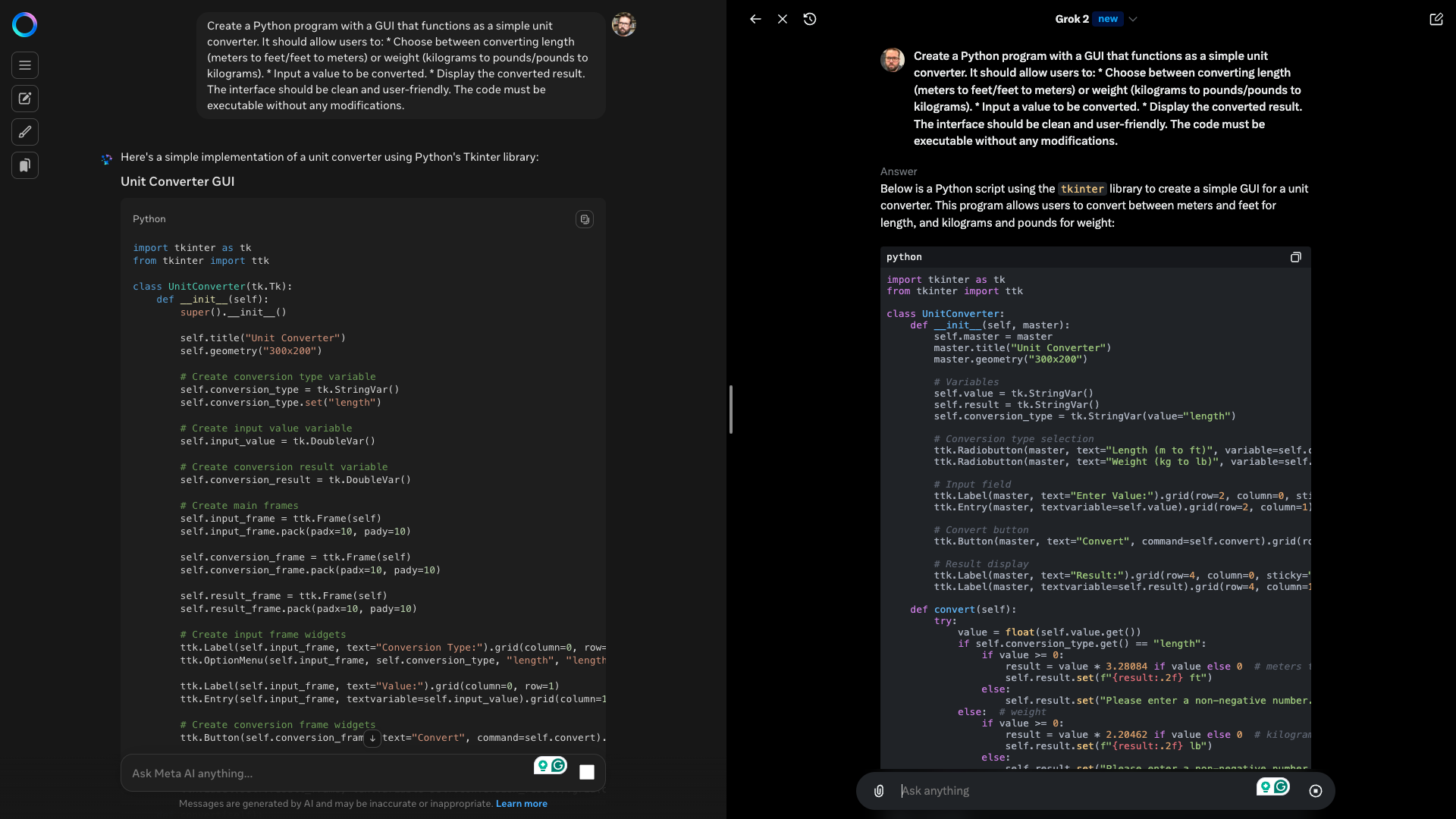
Here Im getting them to create a simple convertor.
In this one were converting length and weight.
Prompt:“Create a Python program with a GUI that functions as a simple unit converter.
Input a value to be converted.
Display the converted result.
The interface should be clean and user-friendly.
The code must be executable without any modifications.”
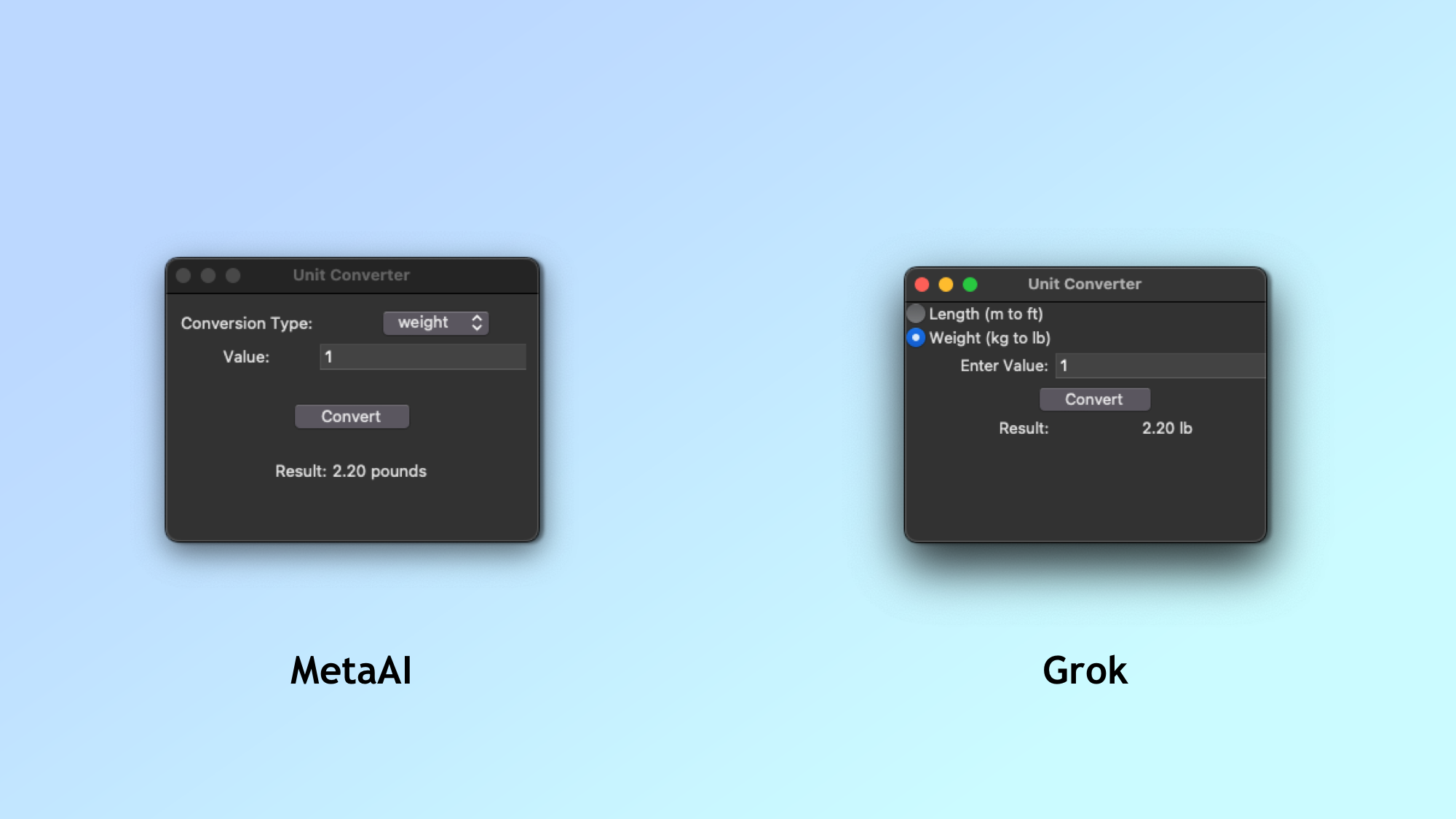
Both apps were surprisingly similar and worked straight out of the box.
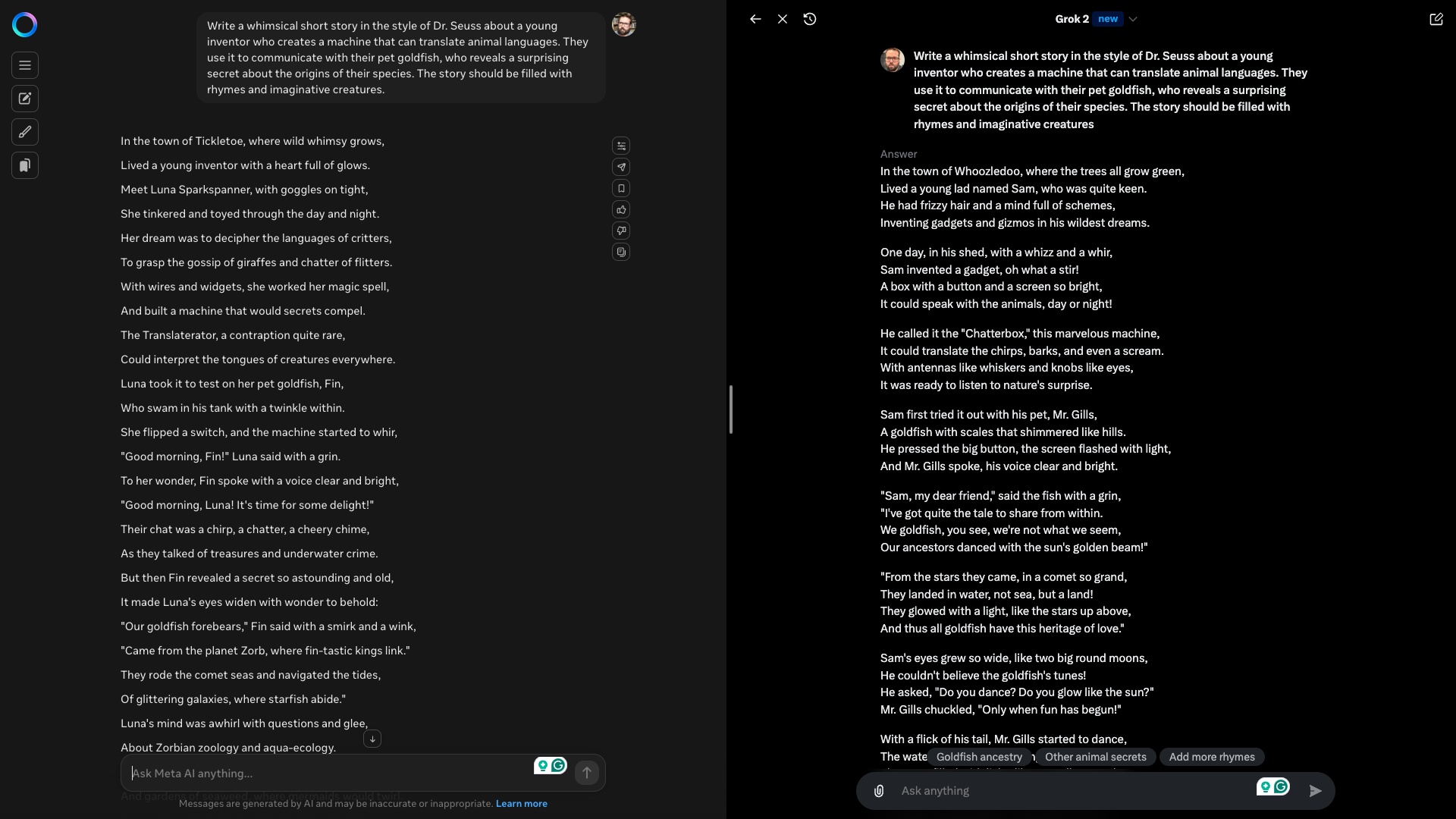
The story should be filled with rhymes and imaginative creatures."
Full report in aGoogle Doc.
MetaAI’s response failed almost immediately for me as it used the word whimsy in the opening line.
This is a little “on the nose” and a sign of a lower-quality AI model.
![]()
They work through the problem step-by-step and provide a solution.
The challenge here is in how well they present that solution for a non-technical audience.
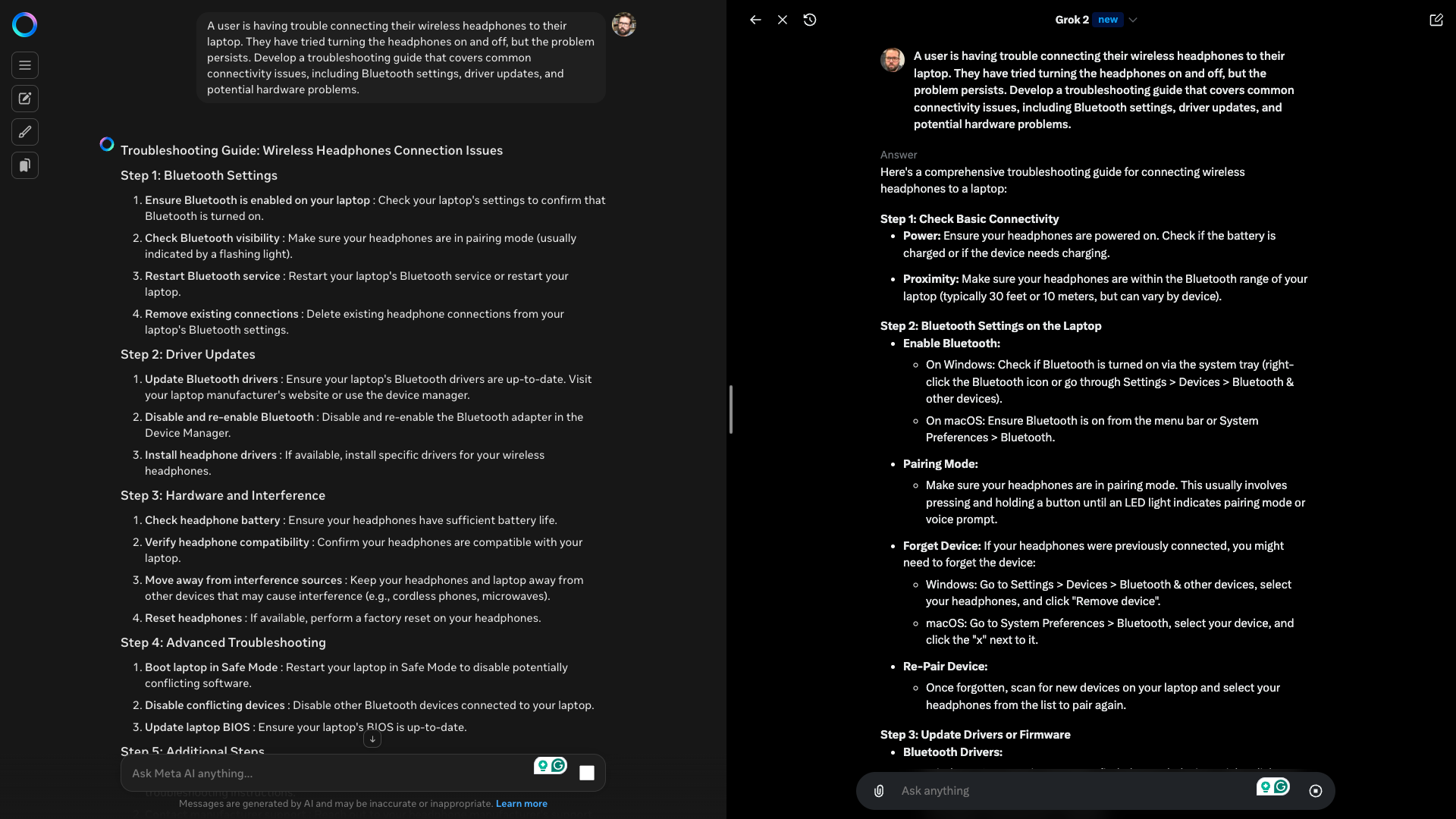
Prompt:“A user is having trouble connecting their wireless headphones to their laptop.
![]()
They have tried turning the headphones on and off, but the problem persists.
Full response available in aGoogle Doc.
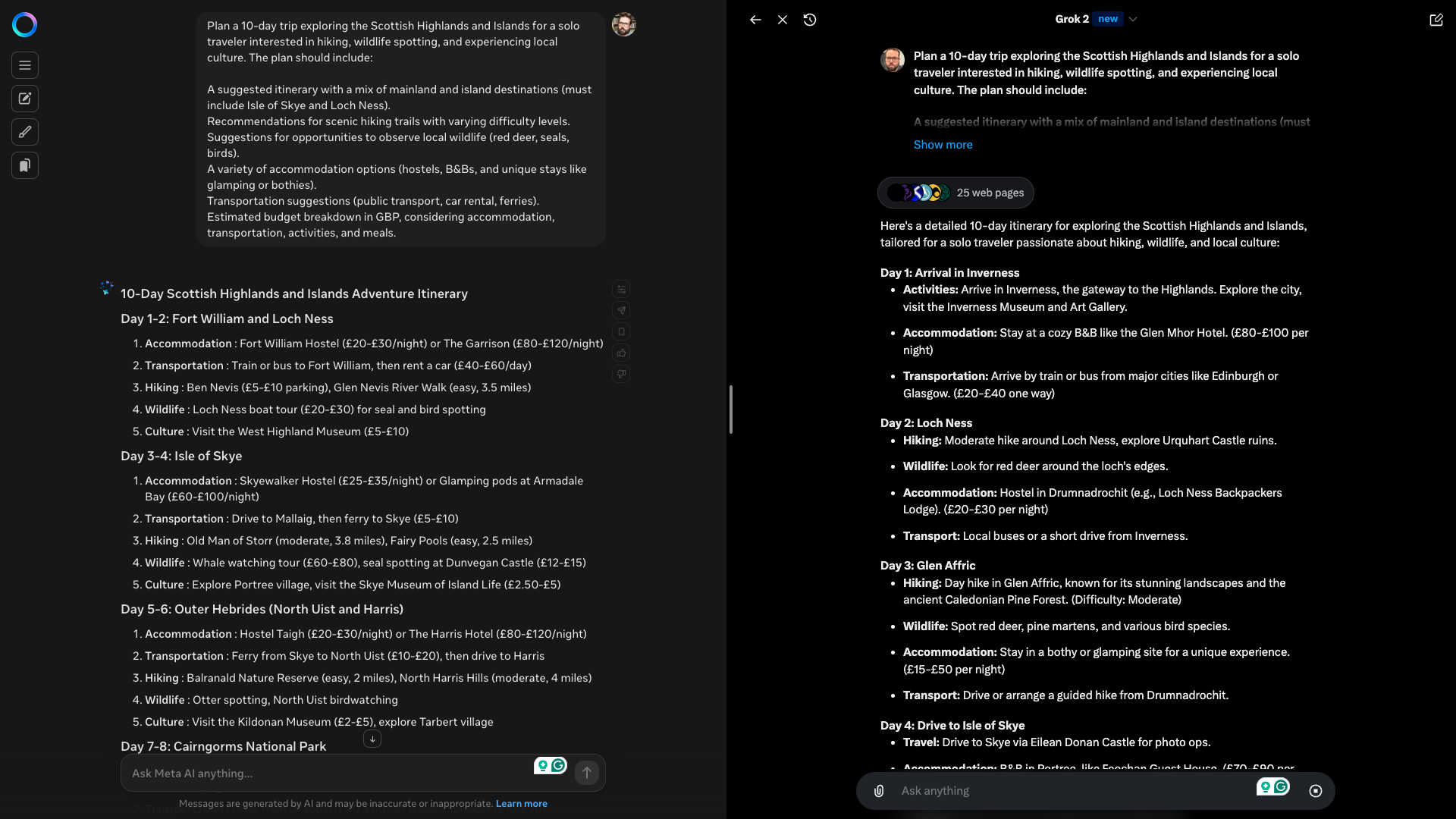
MetaAI didn’t do a bad job.

Grok just did it better with a more concrete plan and fallback options.
Full details in aGoogle Doc.
Similar responses, but as with the other responses, Grok was more personal and engaging.

It was generally better overall with more nuance and detail.
Education
Finally, were testing how well AI manages to explain a complex topic to a specific audience.
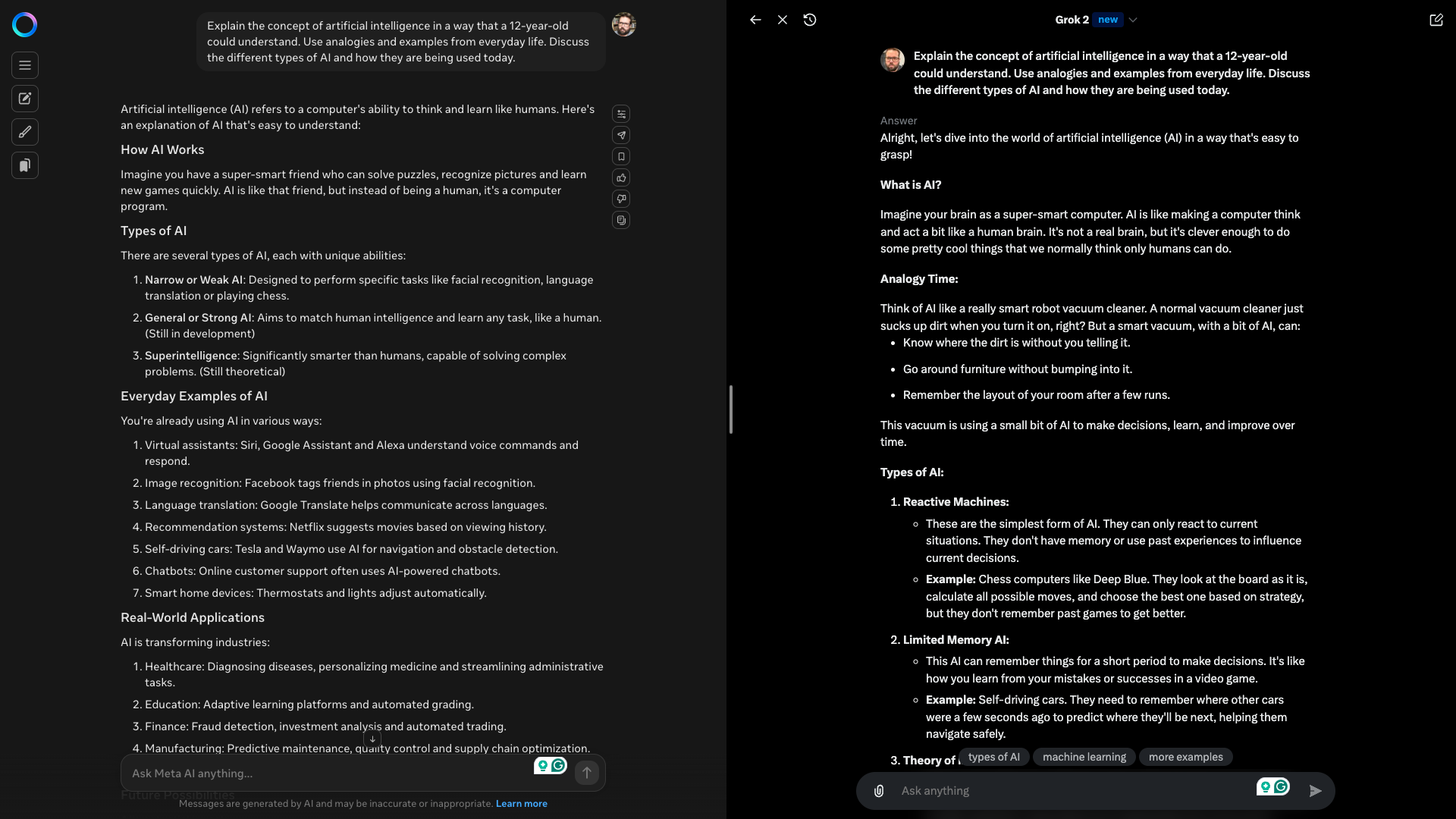
Here Ive asked it to explain the concept of artificial intelligence to a 12-year-old.

This has to include a break down by topic and show everyday examples.
Prompt:“Explain the concept of artificial intelligence in a way that a 12-year-old could understand.
Use analogies and examples from everyday life.

Discuss the different types of AI and how they are being used today.”
Full responses in aGoogle Doc.
Grok is proving itself to be something special.

MetaAI isn’t a bad model, it just isn’t in the same league as Grok.
The analysis for each response has been pretty much the same throughout.
Grok simply outclassed MetaAI.

Llama 3.2 400b is a good underlying model.
It is open-source and powers a lot of applications but Grok is better.
That might change with Llama 4 and Grok 3, but for now Grok wins.

More from Tom’s Guide


















