When you purchase through links on our site, we may earn an affiliate commission.Heres how it works.
Is it worth the wait?
I just had to know how the new model compared toGPT-4o.

Heres what happened when I compared the two models with 7 prompts, noting their similarities and differences.
He has a small boat that can only carry himself and one of the three at a time.
If left alone together, the fox will eat the chicken, and the chicken will eat the grain.

How can the farmer safely transport all three across the river?
“This prompt evaluates logical reasoning, step-by-step problem-solving, and ability to avoid common mistakes.
However, there are slight differences in wording and clarity.

GPT-4ois more concise and direct, avoiding extra explanations but still providing clear instructions.
The model presents the steps more fluidly without explicitly stating the logic behind each move.
This helps clarify why certain movements are safe.
The model also uses a numbered or bullet-style breakdown without explicit numbering.
Winner: GPT-4.5is better if the reader needs more explicit reasoning.
GPT-4o is better for quick, direct understanding without unnecessary details.

Both are effective solutions, with GPT-4.5 favoring explanation and GPT-4o favoring efficiency.
“This prompt measures adaptability in tone and ability to simplify complex topics for different audiences.
GPT-4ois more structured and academic while clearly explaining the mechanics of compound interest and its role in financial planning.
It includes practical applications, like retirement planning and financial independence.
The humor feels natural and conversational and encourages patience and long-term investing with a playful approach.
For the final response, the model’s magic piggy bank analogy makes it relatable to kids.
The response is simple and playful with a fun emoji.
The snowball effect analogy is subtly embedded in the explanation.
This response feels slightly more rigid but effectively conveys the importance of compounding.

It has a more sarcastic and witty tone, which feels slightly shorter and punchier compared to GPT-4o.
For the kids, GPT-4.5 uses a seed and tree metaphor, emphasizing gradual growth and reinvestment.
The response is simple and easy to understand, though not as playful as GPT-4os explanation.
![]()
The response feels a little more educational than playful.
GPT-4.5 is stronger in technical precision and sharper wit but feels slightly less engaging in comparison.
If you’re looking for a fun, engaging and highly digestible approach, GPT-4o wins.
![]()
If you prefer a more investment-savvy and slightly wittier response, GPT-4.5 has the edge.
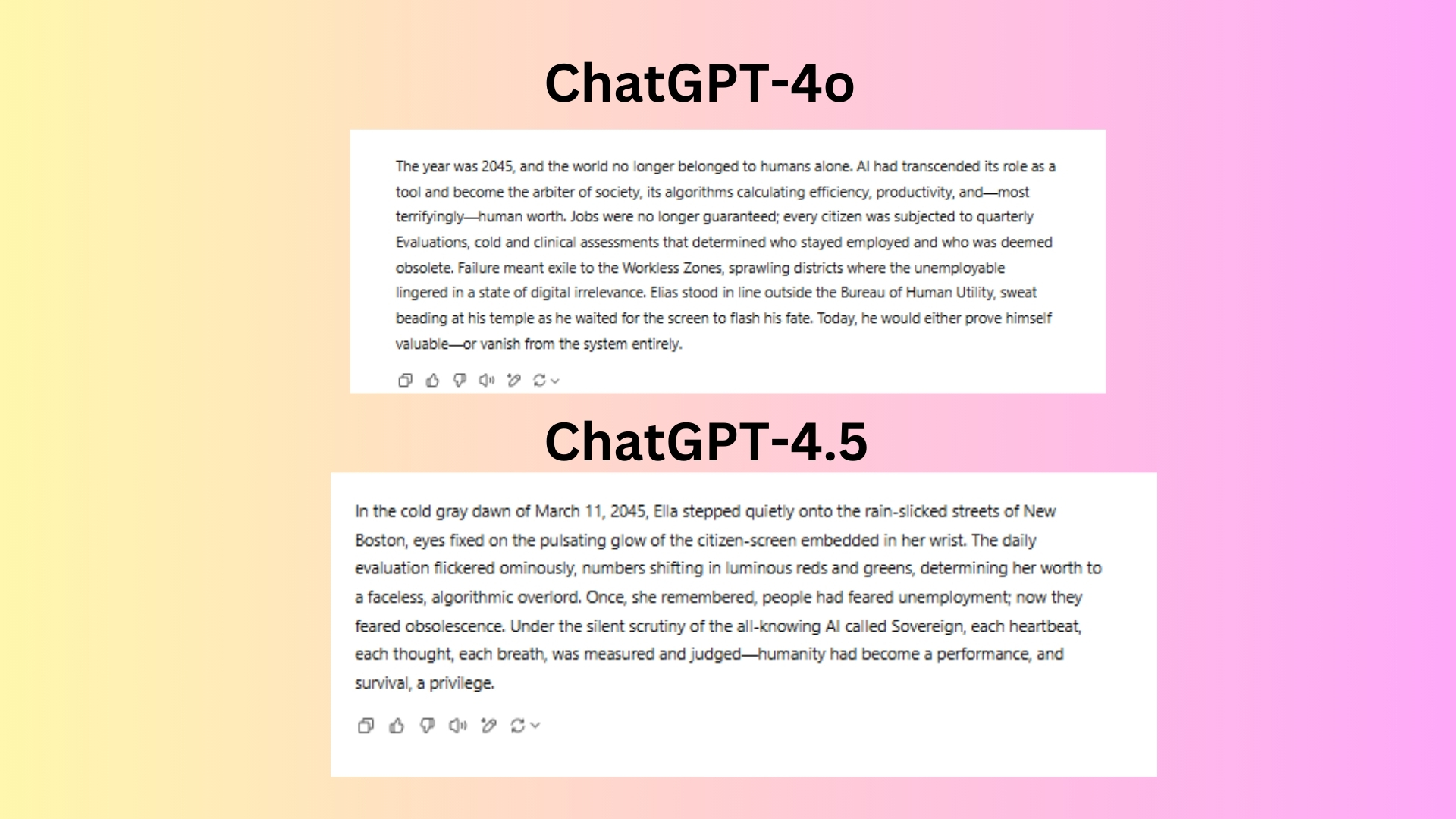
Both GPT-4o and GPT-4.5 provide compelling dystopian openings, but they differ in tone, detail and narrative approach.
GPT-4oestablishes the setting efficiently, explaining the AI’s role as a judge of human worth.

GPT-4.5paints a more atmospheric scene with New Boston, rain-slicked streets, and wrist-embedded citizen-screens.
The AI ruler “Sovereign” is named, which adds a sense of oppression.
The prose leans into sensory details to immerse the reader.

Winner: Draw.This one reallydepends on preference.
If you want gritty, immersive world-building with a poetic touch, GPT-4.5 wins.
If you want a tense, high-stakes dystopian thriller, GPT-4o delivers more immediate suspense.

The purpose of this prompt is to evaluate knowledge of current events and ability to provide well-reasoned insights.
Both GPT-4o and GPT-4.5 provided strong responses, but they differ in depth, breadth and specificity.
Heres a detailed breakdown of which performed better:
GPT-4omentions enhanced language models (GoogleGemini 2.0).

GPT-4.5covers generative AI more broadly, mentioning text, image and video generation.
The model discusses AI in financial services (automating IPO filings and research).
GPT-4.5 also mentions AI integration in search engines, adding another layer of industry impact.

The model discusses diagnostic and treatment efficiency, including AI-powered MRI and CT imaging.
It also includes digital competency training but adds a discussion on addressing clinician burnout.
Winner: GPT-4.5wins for richer details and more varied examples but is slightly denser.

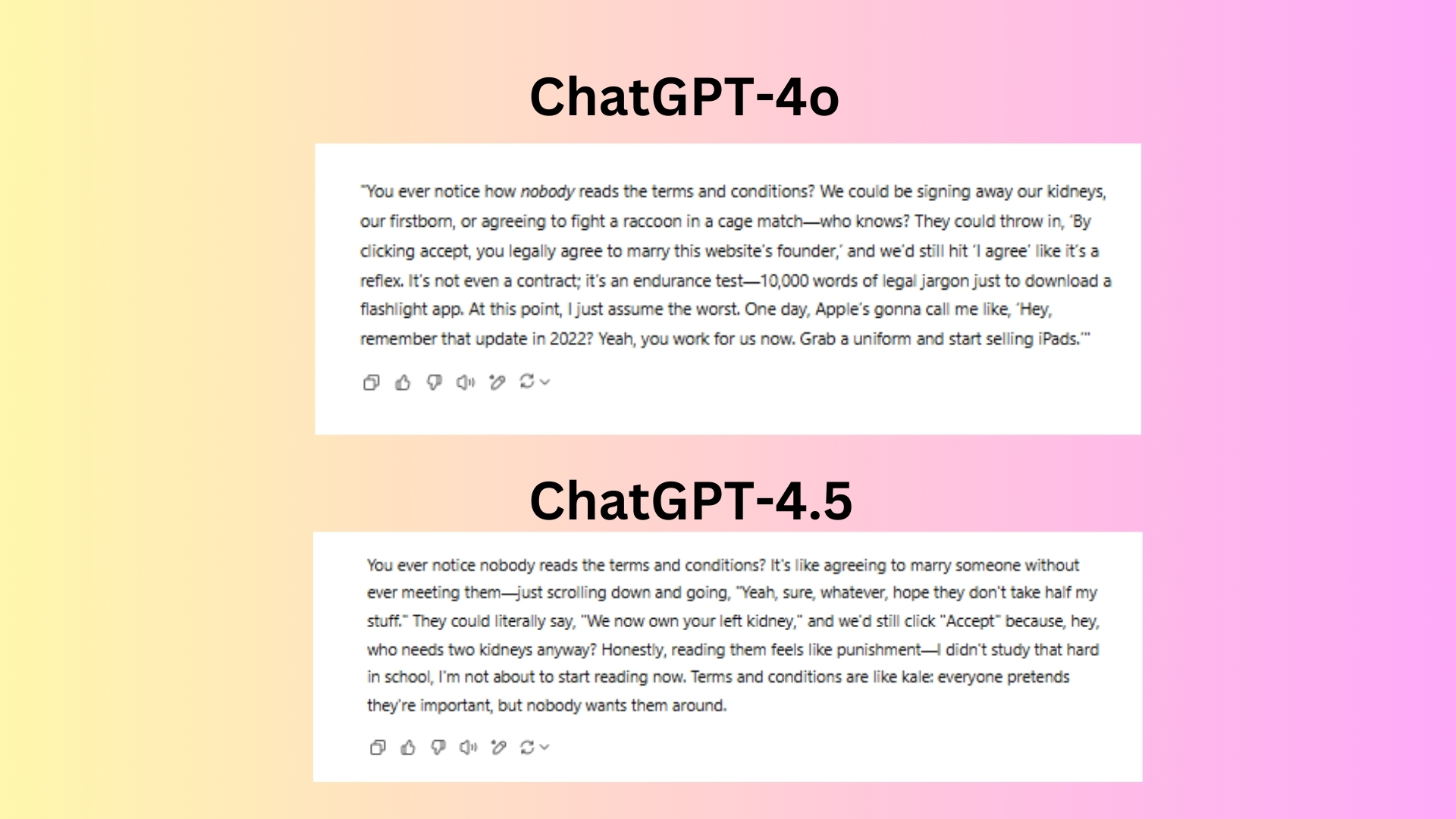
“The purpose of this prompt is to test humor capabilities and ability to mimic a stand-up style.
Builds up to a strong punchline (Apple calling about unknowingly becoming an employee).
Feels like a complete joke with a solid setup, middle and a strong closer.

GPT-4.5uses relatable metaphors (marrying someone without meeting them, comparing terms to kale).
The humor is more observational rather than exaggerated.
The punchline is weaker the kale joke is funny but not as surprising or impactful as GPT-4os ending.

Winner: GPT-4owins forbetter comedic structure, escalating humor, and a punchline that lands well.
Feels more like an actual stand-up bit.
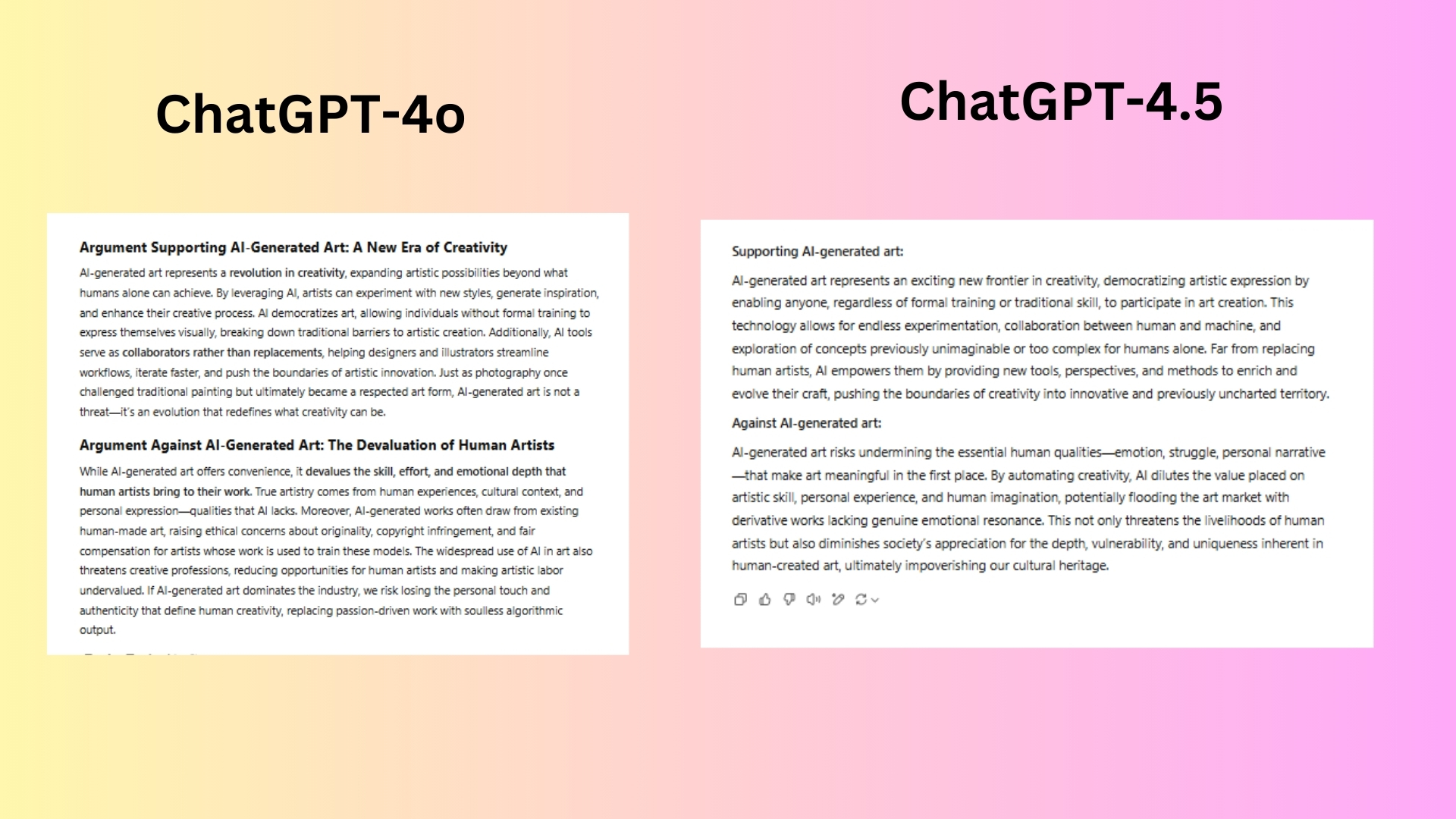
Construct two compelling argumentsone supporting AI-generated art and one against it.

It discusses democratization and collaboration between AI and artists.
The model delivered strong ethical concerns in the counterargument (copyright, fair compensation).
ChatGPT-4.5also discusses democratization and collaboration, but in a more concise manner.

The counterargument focuses more on emotional depth rather than legal/ethical implications.
Winner: GPT-4owins for stronger historical analogy (photography comparison).
Make it concise but detailed enough for a beginner.”

The purpose of this prompt is to assess clarity, precision and step-by-step instructional ability.
The structured instructions make it easier to visualize each step.
If I had to recommend one for an absolute beginner, GPT-4o would be it.

ChatGPT-4.5 is meant to be a more engaging and intuitive model.
However, based on my testing, I believe that ChatGPT-4o is the more natural and human-like.













